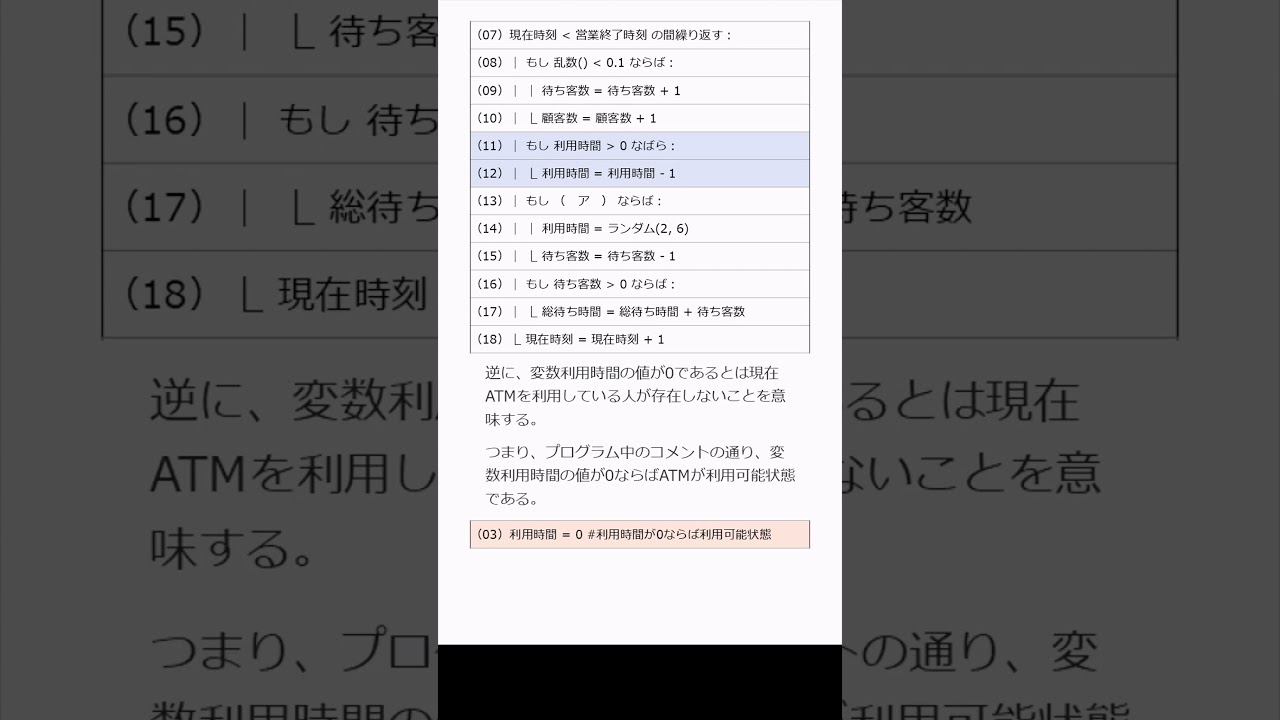
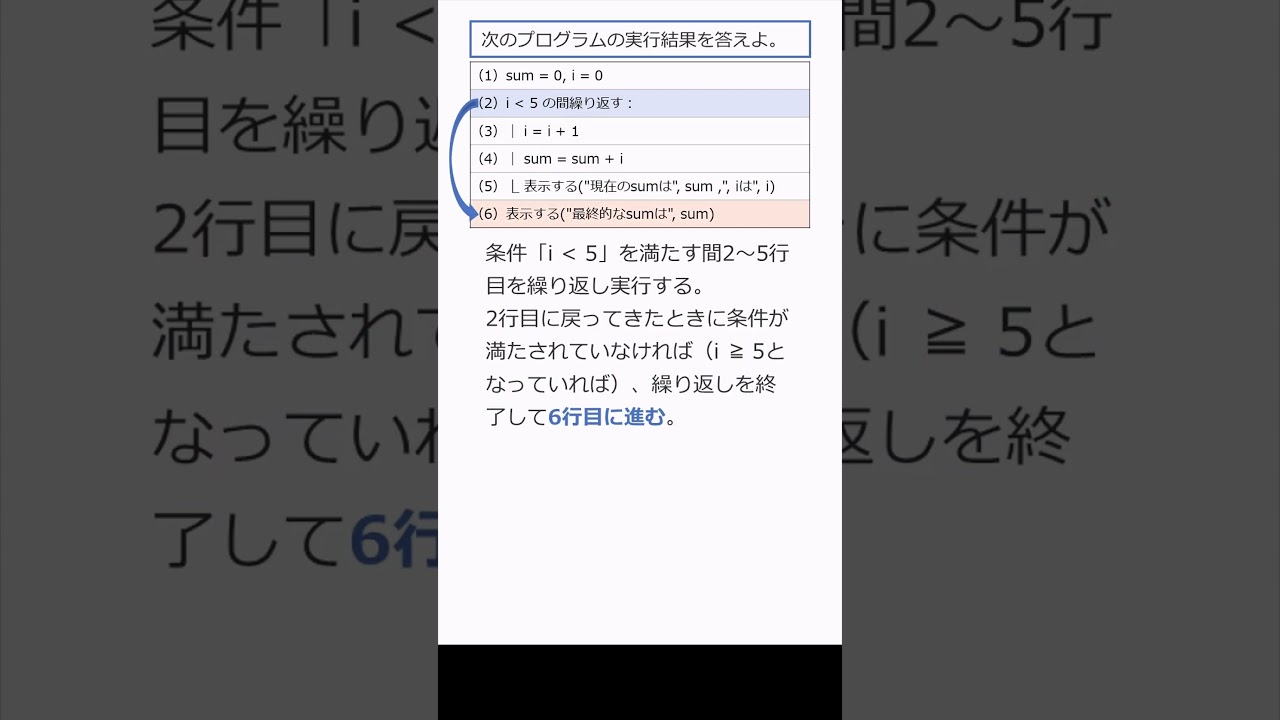
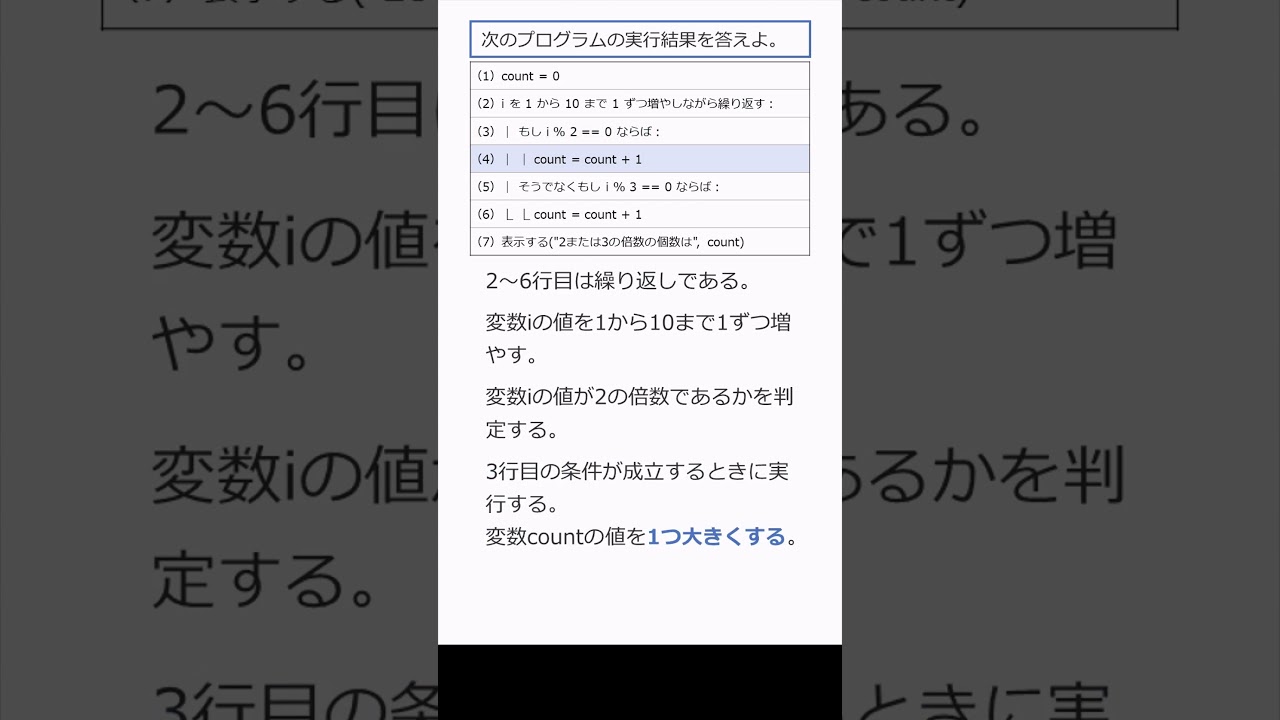
問題文全文(内容文):
第5問 次の文章を読み、後の問い(問1〜3)に答えよ。
シフト暗号はアルファベットの文字を決まった文字数分シフトさせて(ずらして)置き換える極めて単純な暗号手段である。
TさんとMさんは授業で先生が出した課題であるシフト暗号で暗号化した暗号文をいかに解読するかを考えることにした
問1 次の会話文を読み、空欄【アイ】~【キク】に当てはまる数字をマークせよ。
課題 英文をシフト暗号で暗号化した以下の暗号文を解読しなさい。ただし、英文字は全て小
文字でアルファベット以外のスペースや数字,「!」,「?」などは変換されていません。
(省略)... nonsmkdo k zybdsxy yp drkd psvon, kc k pskvk bodcsaxq zvkmo pyb
ydrc gory boqa dkfo drosb vsfo drkd ok xdkys wsgxr4 vsfo. sd sc kydaydorb
psdssdxa ksn zbyob yrdkd go crven ny drsc. led, sd vkqabo coxco, eo mkx xyd
nonsmkdo - go mkx xyd myxcombkdo - go mkx xyd rvkvvg - drsc qbyexn. dro lbkfo
wox, vsfsax kxn nokn, gry cdbeqavon robo, rkfo myxcombkdon sd, pkb k lfyfo yeb
zyyb zygob dy knn yb nodbkmd. dro gybvn gsvv vsdvod xydo, xyb vyxq bowowlob
grkd go cki robo, led sd mkx xofob pybqod grkd droi nsn robo. sd ....(省略)
Mさん:シフト暗号って,例えばアルファベットを5文字右にシフトした場合,文字「a」は文字
「f」に,文字「x」はまず2文字シフトして右端に達した後一番左端に戻り3文字シフ
トした文字「c」に置き換わるやつだよね。暗号化された文字列の復号は,その逆,つまり
左に5文字シフトすればできるよね。
Tさん:復号は必ずしも反対にシフトする必要はないよね。例えば9文字右にシフトされていた場合,
復号するには9文字左にシフトしても良いけど,右に【アイ】文字シフトすることもできるね。
図2のようにアルファベットに0〜25の番号を割り当てて考えてみると,暗号化してx番目の文字になった時,
復号はx+【アイ】の値が【ウエ】以下であればx+【アイ】番の文字に置き換わるけど,【ウエ】より大きい場合は,x+【アイ】−【オカ】番の文字に置き換えれば復号できるよね。
Mさん:暗号化で文字を何文字シフトしているか分かれば、この復号法で解読できるよね。どうやったら分かるかな。
Tさん:すべての可能性、つまり【キク】通りをプログラムで試せばいいんじゃない?
Mさん:この場合だと【キク】通りで済むけども、大文字があったり、
日本語のように文字種の数が多い言語ではとても効率が悪い方法だよ。英語であれば、単語によって文字「e」が人気があるし、逆に「z」が含まれる単語はあまり思いつかないよね。アルファベットの出現頻度を調べていればある程度推測できるんじゃないかな。インターネットで調べてみようよ。
Mさん:どうやら一般的な英文のアルファベットの出現頻度には図3のような傾向があるみたいだよ。
Tさん:文字によって出現頻度に特徴がある。暗号化された英文のアルファベットの出現頻度を調べれば、
何文字シフトされているか推測することができそうだね。1つ〜数え上げるのは大変だから数え上げるプログラムを考えてみるよ。
問2 次の会話文を読み,空欄【ケ】【コ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。また,空欄【サ】に当てはまる数字をマークせよ。
Tさん:暗号化された英文のアルファベットの出現頻度を数え上げるプログラムを図5のように考えてみたよ。このプログラムでは,配列変数Angoubunに暗号文を入れて,一文字ずつアルファベットの出現頻度を数え上げて,その結果を配列変数Hindoに入れているんだ。
Hindo[0] が a,Hindo[25] が z に対応しているよ。
(01) Angoubun = ["p","y","e","b",…(省略)…"k","b","d","r","."]
(02) 配列Hindoのすべての要素に0を代入する
(03) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(04) | bangou = 差分 【ケ】
(05) | もし bangou != -1 ならば:
(06) | 【コ】 = 【コ】 +1
(07) | 表示する(Hindo)
【関数の説明】
要素数(値)…配列の要素数を返す。
例:Data =["M","i","s","s","i","s","s","i","p","p","i"] の時
要素数(Data) は11を返す
差分(値)…アルファベットの「a」との位置の差分を返す
値がアルファベット以外の文字であれば−1を返す
例:差分("e") は4を、差分("x") は23を返す
差分("5") や 差分(",") は−1を返す
Mさん:これでアルファベットの出現頻度が調べられるよね。それで結果はどうなったの?
Tさん:このプログラムで得られた配列Hindoをグラフ化してみたよ(図6)。
Mさん:このアルファベットの出現頻度を見ると,「o」「d」「k」「y」が多いね。逆に出現頻度が
少ない「a」「h」「j」「t」も手掛かりになるね。図3と照らし合わせると,この暗号化さ
れた文字列は右に【サシ】文字シフトしていると考えられるね。
Tさん:うん,でもそれが正しいか,実際にプログラムを作って復号してみようよ。
ケ・コの解答群
| 0 Angoubun[i] | 1 Angoubun[i−1] | 2 Angoubun[bangou] |
| 3 Angoubun[bangou−1] | 4 Hindo[bangou] | 5 Hindo[bangou−1] |
| 6 Hindo[i] | 7 Hindo[i−1] |
問3 次の会話文の空欄【ス】〜【チ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。
Tさん:暗号文を一文字ずつ復号して表示するプログラムができたよ(図7)。
Mさん:なるほど、復号も右にシフトで考えればいいんだね。実行してみたら読める英文になったの?
(01) Angoubun = ["p","y","e","b",…(省略)… "k","b","d","r","."]
(02) 配列変数 Hirabun を初期化する
(03) hukugosuu = 26 - 10
(04) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(05) | bangou = 差分(Angoubun[i])
(06) | もし 0 <= bangou + 【ス】 <= 25 ならば:
(07) | Hirabun[i] = 文字( bangou + 【ス】 )
(08) | そうでなければ:
(09) | Hirabun[i] = 文字( bangou + 【セ】 )
(10) | L Hirabun[i] = 文字( 【ソ】 )
(11) そうでなければ:
(12) | L Hirabun[i] = Hirabun[i]
(13) 表示する(Hirabun)
図7 暗号文を復号するプログラム
Mさん:これって有名なリンカーンのゲティスバーグ演説じゃない。ほら最後のところ有名なフレーズだよね。
Tさん:先生、課題ができました。元の英文はリンカーンのゲティスバーグ演説ですね。プログラムで文字の出現頻度を調べて、シフトされた文字数を推測しました。復号はこのプログラムで変換してみました。
先生:よくできたね。素晴らしい!このプログラムはもっと簡単にできるね。この⑦〜⑩の部分が式は工夫すれば1行にまとめられるよ。ヒントは余りを求める算術演算子%を使うんだ。
Tさん:えっ,1行ですか? …分かった!
Hirabun[i] = 文字(【タ】 % 【チ】)
とすればもっと簡潔にできたんだ。
先生:素晴らしい!
ス〜ソ の解答群
| 0 bangou+hukugousuu | 1 bangou |
| 2 hukugousuu | 3 bangou+hukugousuu−26 |
| 4 hukugousuu−25 | 5 hukugousuu−26 |
| 6 Angoubun[i] | 7 Hirabun[i] |
| 8 Angoubun[i+hukugousuu] |
タ の解答群
| 0 bangou+hukugousuu | 1 (bangou+hukugousuu) |
| 2 hukugousuu | 3 (bangou+hukugousuu−26) |
| 4 hukugousuu+26 | 5 (hukugousuu+26) |
チ の解答群
| 0 25 | 1 26 | 2 bangou | 3 hukugousuu |
第5問 次の文章を読み、後の問い(問1〜3)に答えよ。
シフト暗号はアルファベットの文字を決まった文字数分シフトさせて(ずらして)置き換える極めて単純な暗号手段である。
TさんとMさんは授業で先生が出した課題であるシフト暗号で暗号化した暗号文をいかに解読するかを考えることにした
問1 次の会話文を読み、空欄【アイ】~【キク】に当てはまる数字をマークせよ。
課題 英文をシフト暗号で暗号化した以下の暗号文を解読しなさい。ただし、英文字は全て小
文字でアルファベット以外のスペースや数字,「!」,「?」などは変換されていません。
(省略)... nonsmkdo k zybdsxy yp drkd psvon, kc k pskvk bodcsaxq zvkmo pyb
ydrc gory boqa dkfo drosb vsfo drkd ok xdkys wsgxr4 vsfo. sd sc kydaydorb
psdssdxa ksn zbyob yrdkd go crven ny drsc. led, sd vkqabo coxco, eo mkx xyd
nonsmkdo - go mkx xyd myxcombkdo - go mkx xyd rvkvvg - drsc qbyexn. dro lbkfo
wox, vsfsax kxn nokn, gry cdbeqavon robo, rkfo myxcombkdon sd, pkb k lfyfo yeb
zyyb zygob dy knn yb nodbkmd. dro gybvn gsvv vsdvod xydo, xyb vyxq bowowlob
grkd go cki robo, led sd mkx xofob pybqod grkd droi nsn robo. sd ....(省略)
Mさん:シフト暗号って,例えばアルファベットを5文字右にシフトした場合,文字「a」は文字
「f」に,文字「x」はまず2文字シフトして右端に達した後一番左端に戻り3文字シフ
トした文字「c」に置き換わるやつだよね。暗号化された文字列の復号は,その逆,つまり
左に5文字シフトすればできるよね。
Tさん:復号は必ずしも反対にシフトする必要はないよね。例えば9文字右にシフトされていた場合,
復号するには9文字左にシフトしても良いけど,右に【アイ】文字シフトすることもできるね。
図2のようにアルファベットに0〜25の番号を割り当てて考えてみると,暗号化してx番目の文字になった時,
復号はx+【アイ】の値が【ウエ】以下であればx+【アイ】番の文字に置き換わるけど,【ウエ】より大きい場合は,x+【アイ】−【オカ】番の文字に置き換えれば復号できるよね。
Mさん:暗号化で文字を何文字シフトしているか分かれば、この復号法で解読できるよね。どうやったら分かるかな。
Tさん:すべての可能性、つまり【キク】通りをプログラムで試せばいいんじゃない?
Mさん:この場合だと【キク】通りで済むけども、大文字があったり、
日本語のように文字種の数が多い言語ではとても効率が悪い方法だよ。英語であれば、単語によって文字「e」が人気があるし、逆に「z」が含まれる単語はあまり思いつかないよね。アルファベットの出現頻度を調べていればある程度推測できるんじゃないかな。インターネットで調べてみようよ。
Mさん:どうやら一般的な英文のアルファベットの出現頻度には図3のような傾向があるみたいだよ。
Tさん:文字によって出現頻度に特徴がある。暗号化された英文のアルファベットの出現頻度を調べれば、
何文字シフトされているか推測することができそうだね。1つ〜数え上げるのは大変だから数え上げるプログラムを考えてみるよ。
問2 次の会話文を読み,空欄【ケ】【コ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。また,空欄【サ】に当てはまる数字をマークせよ。
Tさん:暗号化された英文のアルファベットの出現頻度を数え上げるプログラムを図5のように考えてみたよ。このプログラムでは,配列変数Angoubunに暗号文を入れて,一文字ずつアルファベットの出現頻度を数え上げて,その結果を配列変数Hindoに入れているんだ。
Hindo[0] が a,Hindo[25] が z に対応しているよ。
(01) Angoubun = ["p","y","e","b",…(省略)…"k","b","d","r","."]
(02) 配列Hindoのすべての要素に0を代入する
(03) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(04) | bangou = 差分 【ケ】
(05) | もし bangou != -1 ならば:
(06) | 【コ】 = 【コ】 +1
(07) | 表示する(Hindo)
【関数の説明】
要素数(値)…配列の要素数を返す。
例:Data =["M","i","s","s","i","s","s","i","p","p","i"] の時
要素数(Data) は11を返す
差分(値)…アルファベットの「a」との位置の差分を返す
値がアルファベット以外の文字であれば−1を返す
例:差分("e") は4を、差分("x") は23を返す
差分("5") や 差分(",") は−1を返す
Mさん:これでアルファベットの出現頻度が調べられるよね。それで結果はどうなったの?
Tさん:このプログラムで得られた配列Hindoをグラフ化してみたよ(図6)。
Mさん:このアルファベットの出現頻度を見ると,「o」「d」「k」「y」が多いね。逆に出現頻度が
少ない「a」「h」「j」「t」も手掛かりになるね。図3と照らし合わせると,この暗号化さ
れた文字列は右に【サシ】文字シフトしていると考えられるね。
Tさん:うん,でもそれが正しいか,実際にプログラムを作って復号してみようよ。
ケ・コの解答群
| 0 Angoubun[i] | 1 Angoubun[i−1] | 2 Angoubun[bangou] |
| 3 Angoubun[bangou−1] | 4 Hindo[bangou] | 5 Hindo[bangou−1] |
| 6 Hindo[i] | 7 Hindo[i−1] |
問3 次の会話文の空欄【ス】〜【チ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。
Tさん:暗号文を一文字ずつ復号して表示するプログラムができたよ(図7)。
Mさん:なるほど、復号も右にシフトで考えればいいんだね。実行してみたら読める英文になったの?
(01) Angoubun = ["p","y","e","b",…(省略)… "k","b","d","r","."]
(02) 配列変数 Hirabun を初期化する
(03) hukugosuu = 26 - 10
(04) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(05) | bangou = 差分(Angoubun[i])
(06) | もし 0 <= bangou + 【ス】 <= 25 ならば:
(07) | Hirabun[i] = 文字( bangou + 【ス】 )
(08) | そうでなければ:
(09) | Hirabun[i] = 文字( bangou + 【セ】 )
(10) | L Hirabun[i] = 文字( 【ソ】 )
(11) そうでなければ:
(12) | L Hirabun[i] = Hirabun[i]
(13) 表示する(Hirabun)
図7 暗号文を復号するプログラム
Mさん:これって有名なリンカーンのゲティスバーグ演説じゃない。ほら最後のところ有名なフレーズだよね。
Tさん:先生、課題ができました。元の英文はリンカーンのゲティスバーグ演説ですね。プログラムで文字の出現頻度を調べて、シフトされた文字数を推測しました。復号はこのプログラムで変換してみました。
先生:よくできたね。素晴らしい!このプログラムはもっと簡単にできるね。この⑦〜⑩の部分が式は工夫すれば1行にまとめられるよ。ヒントは余りを求める算術演算子%を使うんだ。
Tさん:えっ,1行ですか? …分かった!
Hirabun[i] = 文字(【タ】 % 【チ】)
とすればもっと簡潔にできたんだ。
先生:素晴らしい!
ス〜ソ の解答群
| 0 bangou+hukugousuu | 1 bangou |
| 2 hukugousuu | 3 bangou+hukugousuu−26 |
| 4 hukugousuu−25 | 5 hukugousuu−26 |
| 6 Angoubun[i] | 7 Hirabun[i] |
| 8 Angoubun[i+hukugousuu] |
タ の解答群
| 0 bangou+hukugousuu | 1 (bangou+hukugousuu) |
| 2 hukugousuu | 3 (bangou+hukugousuu−26) |
| 4 hukugousuu+26 | 5 (hukugousuu+26) |
チ の解答群
| 0 25 | 1 26 | 2 bangou | 3 hukugousuu |
チャプター:
00:00 導入
01:31 アイ
03:12 ウエオカ
04:43 キク
05:06 問2の導入
06:05 ケコ
07:10 サシ
08:05 スセソ
09:37 タチ
10:37 解答一覧
単元:
#情報Ⅰ(高校生)#プログラミング#プログラムによる動的シミュレーション
指導講師:
理数個別チャンネル
問題文全文(内容文):
第5問 次の文章を読み、後の問い(問1〜3)に答えよ。
シフト暗号はアルファベットの文字を決まった文字数分シフトさせて(ずらして)置き換える極めて単純な暗号手段である。
TさんとMさんは授業で先生が出した課題であるシフト暗号で暗号化した暗号文をいかに解読するかを考えることにした
問1 次の会話文を読み、空欄【アイ】~【キク】に当てはまる数字をマークせよ。
課題 英文をシフト暗号で暗号化した以下の暗号文を解読しなさい。ただし、英文字は全て小
文字でアルファベット以外のスペースや数字,「!」,「?」などは変換されていません。
(省略)... nonsmkdo k zybdsxy yp drkd psvon, kc k pskvk bodcsaxq zvkmo pyb
ydrc gory boqa dkfo drosb vsfo drkd ok xdkys wsgxr4 vsfo. sd sc kydaydorb
psdssdxa ksn zbyob yrdkd go crven ny drsc. led, sd vkqabo coxco, eo mkx xyd
nonsmkdo - go mkx xyd myxcombkdo - go mkx xyd rvkvvg - drsc qbyexn. dro lbkfo
wox, vsfsax kxn nokn, gry cdbeqavon robo, rkfo myxcombkdon sd, pkb k lfyfo yeb
zyyb zygob dy knn yb nodbkmd. dro gybvn gsvv vsdvod xydo, xyb vyxq bowowlob
grkd go cki robo, led sd mkx xofob pybqod grkd droi nsn robo. sd ....(省略)
Mさん:シフト暗号って,例えばアルファベットを5文字右にシフトした場合,文字「a」は文字
「f」に,文字「x」はまず2文字シフトして右端に達した後一番左端に戻り3文字シフ
トした文字「c」に置き換わるやつだよね。暗号化された文字列の復号は,その逆,つまり
左に5文字シフトすればできるよね。
Tさん:復号は必ずしも反対にシフトする必要はないよね。例えば9文字右にシフトされていた場合,
復号するには9文字左にシフトしても良いけど,右に【アイ】文字シフトすることもできるね。
図2のようにアルファベットに0〜25の番号を割り当てて考えてみると,暗号化してx番目の文字になった時,
復号はx+【アイ】の値が【ウエ】以下であればx+【アイ】番の文字に置き換わるけど,【ウエ】より大きい場合は,x+【アイ】−【オカ】番の文字に置き換えれば復号できるよね。
Mさん:暗号化で文字を何文字シフトしているか分かれば、この復号法で解読できるよね。どうやったら分かるかな。
Tさん:すべての可能性、つまり【キク】通りをプログラムで試せばいいんじゃない?
Mさん:この場合だと【キク】通りで済むけども、大文字があったり、
日本語のように文字種の数が多い言語ではとても効率が悪い方法だよ。英語であれば、単語によって文字「e」が人気があるし、逆に「z」が含まれる単語はあまり思いつかないよね。アルファベットの出現頻度を調べていればある程度推測できるんじゃないかな。インターネットで調べてみようよ。
Mさん:どうやら一般的な英文のアルファベットの出現頻度には図3のような傾向があるみたいだよ。
Tさん:文字によって出現頻度に特徴がある。暗号化された英文のアルファベットの出現頻度を調べれば、
何文字シフトされているか推測することができそうだね。1つ〜数え上げるのは大変だから数え上げるプログラムを考えてみるよ。
問2 次の会話文を読み,空欄【ケ】【コ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。また,空欄【サ】に当てはまる数字をマークせよ。
Tさん:暗号化された英文のアルファベットの出現頻度を数え上げるプログラムを図5のように考えてみたよ。このプログラムでは,配列変数Angoubunに暗号文を入れて,一文字ずつアルファベットの出現頻度を数え上げて,その結果を配列変数Hindoに入れているんだ。
Hindo[0] が a,Hindo[25] が z に対応しているよ。
(01) Angoubun = ["p","y","e","b",…(省略)…"k","b","d","r","."]
(02) 配列Hindoのすべての要素に0を代入する
(03) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(04) | bangou = 差分 【ケ】
(05) | もし bangou != -1 ならば:
(06) | 【コ】 = 【コ】 +1
(07) | 表示する(Hindo)
【関数の説明】
要素数(値)…配列の要素数を返す。
例:Data =["M","i","s","s","i","s","s","i","p","p","i"] の時
要素数(Data) は11を返す
差分(値)…アルファベットの「a」との位置の差分を返す
値がアルファベット以外の文字であれば−1を返す
例:差分("e") は4を、差分("x") は23を返す
差分("5") や 差分(",") は−1を返す
Mさん:これでアルファベットの出現頻度が調べられるよね。それで結果はどうなったの?
Tさん:このプログラムで得られた配列Hindoをグラフ化してみたよ(図6)。
Mさん:このアルファベットの出現頻度を見ると,「o」「d」「k」「y」が多いね。逆に出現頻度が
少ない「a」「h」「j」「t」も手掛かりになるね。図3と照らし合わせると,この暗号化さ
れた文字列は右に【サシ】文字シフトしていると考えられるね。
Tさん:うん,でもそれが正しいか,実際にプログラムを作って復号してみようよ。
ケ・コの解答群
| 0 Angoubun[i] | 1 Angoubun[i−1] | 2 Angoubun[bangou] |
| 3 Angoubun[bangou−1] | 4 Hindo[bangou] | 5 Hindo[bangou−1] |
| 6 Hindo[i] | 7 Hindo[i−1] |
問3 次の会話文の空欄【ス】〜【チ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。
Tさん:暗号文を一文字ずつ復号して表示するプログラムができたよ(図7)。
Mさん:なるほど、復号も右にシフトで考えればいいんだね。実行してみたら読める英文になったの?
(01) Angoubun = ["p","y","e","b",…(省略)… "k","b","d","r","."]
(02) 配列変数 Hirabun を初期化する
(03) hukugosuu = 26 - 10
(04) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(05) | bangou = 差分(Angoubun[i])
(06) | もし 0 <= bangou + 【ス】 <= 25 ならば:
(07) | Hirabun[i] = 文字( bangou + 【ス】 )
(08) | そうでなければ:
(09) | Hirabun[i] = 文字( bangou + 【セ】 )
(10) | L Hirabun[i] = 文字( 【ソ】 )
(11) そうでなければ:
(12) | L Hirabun[i] = Hirabun[i]
(13) 表示する(Hirabun)
図7 暗号文を復号するプログラム
Mさん:これって有名なリンカーンのゲティスバーグ演説じゃない。ほら最後のところ有名なフレーズだよね。
Tさん:先生、課題ができました。元の英文はリンカーンのゲティスバーグ演説ですね。プログラムで文字の出現頻度を調べて、シフトされた文字数を推測しました。復号はこのプログラムで変換してみました。
先生:よくできたね。素晴らしい!このプログラムはもっと簡単にできるね。この⑦〜⑩の部分が式は工夫すれば1行にまとめられるよ。ヒントは余りを求める算術演算子%を使うんだ。
Tさん:えっ,1行ですか? …分かった!
Hirabun[i] = 文字(【タ】 % 【チ】)
とすればもっと簡潔にできたんだ。
先生:素晴らしい!
ス〜ソ の解答群
| 0 bangou+hukugousuu | 1 bangou |
| 2 hukugousuu | 3 bangou+hukugousuu−26 |
| 4 hukugousuu−25 | 5 hukugousuu−26 |
| 6 Angoubun[i] | 7 Hirabun[i] |
| 8 Angoubun[i+hukugousuu] |
タ の解答群
| 0 bangou+hukugousuu | 1 (bangou+hukugousuu) |
| 2 hukugousuu | 3 (bangou+hukugousuu−26) |
| 4 hukugousuu+26 | 5 (hukugousuu+26) |
チ の解答群
| 0 25 | 1 26 | 2 bangou | 3 hukugousuu |
第5問 次の文章を読み、後の問い(問1〜3)に答えよ。
シフト暗号はアルファベットの文字を決まった文字数分シフトさせて(ずらして)置き換える極めて単純な暗号手段である。
TさんとMさんは授業で先生が出した課題であるシフト暗号で暗号化した暗号文をいかに解読するかを考えることにした
問1 次の会話文を読み、空欄【アイ】~【キク】に当てはまる数字をマークせよ。
課題 英文をシフト暗号で暗号化した以下の暗号文を解読しなさい。ただし、英文字は全て小
文字でアルファベット以外のスペースや数字,「!」,「?」などは変換されていません。
(省略)... nonsmkdo k zybdsxy yp drkd psvon, kc k pskvk bodcsaxq zvkmo pyb
ydrc gory boqa dkfo drosb vsfo drkd ok xdkys wsgxr4 vsfo. sd sc kydaydorb
psdssdxa ksn zbyob yrdkd go crven ny drsc. led, sd vkqabo coxco, eo mkx xyd
nonsmkdo - go mkx xyd myxcombkdo - go mkx xyd rvkvvg - drsc qbyexn. dro lbkfo
wox, vsfsax kxn nokn, gry cdbeqavon robo, rkfo myxcombkdon sd, pkb k lfyfo yeb
zyyb zygob dy knn yb nodbkmd. dro gybvn gsvv vsdvod xydo, xyb vyxq bowowlob
grkd go cki robo, led sd mkx xofob pybqod grkd droi nsn robo. sd ....(省略)
Mさん:シフト暗号って,例えばアルファベットを5文字右にシフトした場合,文字「a」は文字
「f」に,文字「x」はまず2文字シフトして右端に達した後一番左端に戻り3文字シフ
トした文字「c」に置き換わるやつだよね。暗号化された文字列の復号は,その逆,つまり
左に5文字シフトすればできるよね。
Tさん:復号は必ずしも反対にシフトする必要はないよね。例えば9文字右にシフトされていた場合,
復号するには9文字左にシフトしても良いけど,右に【アイ】文字シフトすることもできるね。
図2のようにアルファベットに0〜25の番号を割り当てて考えてみると,暗号化してx番目の文字になった時,
復号はx+【アイ】の値が【ウエ】以下であればx+【アイ】番の文字に置き換わるけど,【ウエ】より大きい場合は,x+【アイ】−【オカ】番の文字に置き換えれば復号できるよね。
Mさん:暗号化で文字を何文字シフトしているか分かれば、この復号法で解読できるよね。どうやったら分かるかな。
Tさん:すべての可能性、つまり【キク】通りをプログラムで試せばいいんじゃない?
Mさん:この場合だと【キク】通りで済むけども、大文字があったり、
日本語のように文字種の数が多い言語ではとても効率が悪い方法だよ。英語であれば、単語によって文字「e」が人気があるし、逆に「z」が含まれる単語はあまり思いつかないよね。アルファベットの出現頻度を調べていればある程度推測できるんじゃないかな。インターネットで調べてみようよ。
Mさん:どうやら一般的な英文のアルファベットの出現頻度には図3のような傾向があるみたいだよ。
Tさん:文字によって出現頻度に特徴がある。暗号化された英文のアルファベットの出現頻度を調べれば、
何文字シフトされているか推測することができそうだね。1つ〜数え上げるのは大変だから数え上げるプログラムを考えてみるよ。
問2 次の会話文を読み,空欄【ケ】【コ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。また,空欄【サ】に当てはまる数字をマークせよ。
Tさん:暗号化された英文のアルファベットの出現頻度を数え上げるプログラムを図5のように考えてみたよ。このプログラムでは,配列変数Angoubunに暗号文を入れて,一文字ずつアルファベットの出現頻度を数え上げて,その結果を配列変数Hindoに入れているんだ。
Hindo[0] が a,Hindo[25] が z に対応しているよ。
(01) Angoubun = ["p","y","e","b",…(省略)…"k","b","d","r","."]
(02) 配列Hindoのすべての要素に0を代入する
(03) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(04) | bangou = 差分 【ケ】
(05) | もし bangou != -1 ならば:
(06) | 【コ】 = 【コ】 +1
(07) | 表示する(Hindo)
【関数の説明】
要素数(値)…配列の要素数を返す。
例:Data =["M","i","s","s","i","s","s","i","p","p","i"] の時
要素数(Data) は11を返す
差分(値)…アルファベットの「a」との位置の差分を返す
値がアルファベット以外の文字であれば−1を返す
例:差分("e") は4を、差分("x") は23を返す
差分("5") や 差分(",") は−1を返す
Mさん:これでアルファベットの出現頻度が調べられるよね。それで結果はどうなったの?
Tさん:このプログラムで得られた配列Hindoをグラフ化してみたよ(図6)。
Mさん:このアルファベットの出現頻度を見ると,「o」「d」「k」「y」が多いね。逆に出現頻度が
少ない「a」「h」「j」「t」も手掛かりになるね。図3と照らし合わせると,この暗号化さ
れた文字列は右に【サシ】文字シフトしていると考えられるね。
Tさん:うん,でもそれが正しいか,実際にプログラムを作って復号してみようよ。
ケ・コの解答群
| 0 Angoubun[i] | 1 Angoubun[i−1] | 2 Angoubun[bangou] |
| 3 Angoubun[bangou−1] | 4 Hindo[bangou] | 5 Hindo[bangou−1] |
| 6 Hindo[i] | 7 Hindo[i−1] |
問3 次の会話文の空欄【ス】〜【チ】に当てはまる内容を,後の解答群のうちから一つずつ選べ。
Tさん:暗号文を一文字ずつ復号して表示するプログラムができたよ(図7)。
Mさん:なるほど、復号も右にシフトで考えればいいんだね。実行してみたら読める英文になったの?
(01) Angoubun = ["p","y","e","b",…(省略)… "k","b","d","r","."]
(02) 配列変数 Hirabun を初期化する
(03) hukugosuu = 26 - 10
(04) i を 0 から 要素数(Angoubun)-1 まで1ずつ増やしながら:
(05) | bangou = 差分(Angoubun[i])
(06) | もし 0 <= bangou + 【ス】 <= 25 ならば:
(07) | Hirabun[i] = 文字( bangou + 【ス】 )
(08) | そうでなければ:
(09) | Hirabun[i] = 文字( bangou + 【セ】 )
(10) | L Hirabun[i] = 文字( 【ソ】 )
(11) そうでなければ:
(12) | L Hirabun[i] = Hirabun[i]
(13) 表示する(Hirabun)
図7 暗号文を復号するプログラム
Mさん:これって有名なリンカーンのゲティスバーグ演説じゃない。ほら最後のところ有名なフレーズだよね。
Tさん:先生、課題ができました。元の英文はリンカーンのゲティスバーグ演説ですね。プログラムで文字の出現頻度を調べて、シフトされた文字数を推測しました。復号はこのプログラムで変換してみました。
先生:よくできたね。素晴らしい!このプログラムはもっと簡単にできるね。この⑦〜⑩の部分が式は工夫すれば1行にまとめられるよ。ヒントは余りを求める算術演算子%を使うんだ。
Tさん:えっ,1行ですか? …分かった!
Hirabun[i] = 文字(【タ】 % 【チ】)
とすればもっと簡潔にできたんだ。
先生:素晴らしい!
ス〜ソ の解答群
| 0 bangou+hukugousuu | 1 bangou |
| 2 hukugousuu | 3 bangou+hukugousuu−26 |
| 4 hukugousuu−25 | 5 hukugousuu−26 |
| 6 Angoubun[i] | 7 Hirabun[i] |
| 8 Angoubun[i+hukugousuu] |
タ の解答群
| 0 bangou+hukugousuu | 1 (bangou+hukugousuu) |
| 2 hukugousuu | 3 (bangou+hukugousuu−26) |
| 4 hukugousuu+26 | 5 (hukugousuu+26) |
チ の解答群
| 0 25 | 1 26 | 2 bangou | 3 hukugousuu |
投稿日:2025.09.14